Science Roboticsに掲載
2022-04-15 株式会社日立製作所
日立と、早稲田大学理工学術院の尾形 哲也(おがた てつや)教授の研究グループは、ロボットの過去の学習内容と現実との差を認識し、次の行動をリアルタイムに決定・実行可能な、深層予測学習型のロボット制御技術を開発しました。本成果は国際学術誌「Science Robotics」に掲載*1されました。本誌はScience誌の姉妹誌であり、2021年7月時点のインパクトファクタ(IF=23.748)はロボット工学分野で最高峰を誇ります*2。
本ロボット制御技術は、生体の脳の働きを解釈可能な自由エネルギー原理*3を参考に、過去の学習内容と現実の差が最小になるように次の動作を決定・実行可能な計算アルゴリズムを考案したもので、未学習の作業内容や環境に対してもロボットが次の作業を柔軟に実行することができます。さらに本技術では、複数の予測モデルのうち、ロボットが状況に応じて予測モデルをリアルタイムに切り替えることで、急な作業内容や環境の変化にも柔軟に対応可能です。
今後、状況が変わりやすくロボットの導入が困難であった作業現場に本技術の適用を図ることにより、ロボットの適用範囲を拡大し、社会の労働力不足の解決をめざします。
現場の状況とモデルの予測誤差を最小化する深層予測学習の
ロボット制御技術を用いて、自律的にドアを開け通過する機能を実証(動画)
開発した技術の詳細
1. 脳機能を参考とする深層予測学習技術

図1 生体が実世界と脳の予測誤差が最小となるように振る舞うことを参考に、現実とモデルの予測誤差を最小化するアルゴリズム「深層予測学習」
従来の機械学習では、ロボットが多様な作業に適用できるように、大規模なデータを用い最適な予測モデルを構築する方式が主に用いられてきました。しかし、実際にはロボットは想定外の事象に遭遇するため、事前に全ての状況に対応できる予測モデルを構築することは困難でした。そこで本研究では、予測モデルの不完全性を前提とし、現場の状況とモデルの予測誤差を最小化するアルゴリズム「深層予測学習」を考案しました。本技術は、生体が実世界と脳の予測誤差が最小となるように振る舞うことを説明する「自由エネルギー原理」を参考に開発したもので、ロボットは視覚運動情報に基づき近未来の状況を予測し、現実との誤差(ギャップ)を最小とするように次の動作を指令します。ロボットは学習時と現実の差を許容しながらリアルタイムに動作を調整し続けることで、未学習の状況下でも柔軟に作業可能です。
2. 深層予測学習を用いた動作生成技術
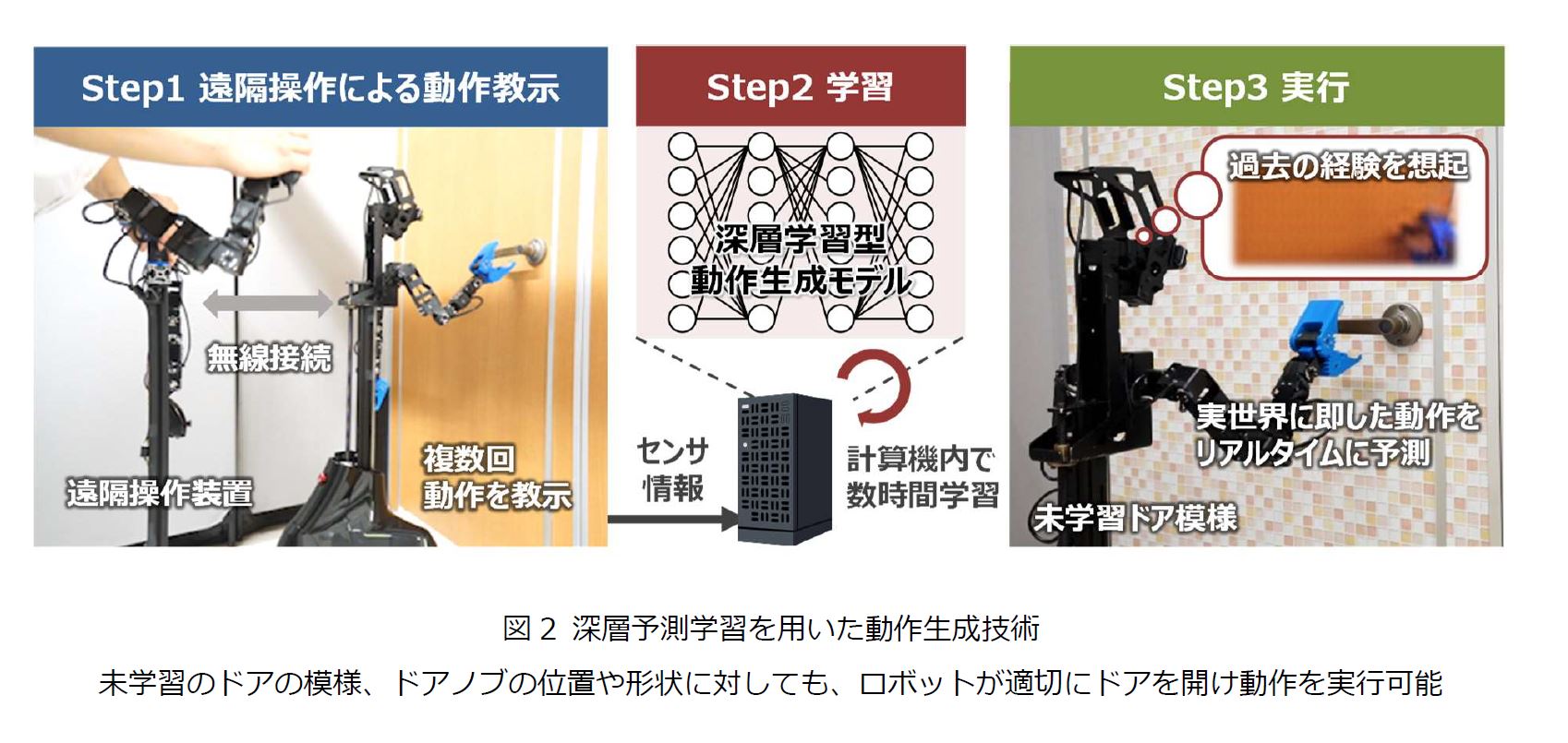
図2 深層予測学習を用いた動作生成技術
未学習のドアの模様、ドアノブの位置や形状に対しても、ロボットが適切にドアを開け動作を実行可能
ロボットの機械学習は従来、所望の動作を獲得するまで膨大な数の試行錯誤をすることで、人が考え付かない効率的な動作を獲得できる反面、機械学習に手間と時間を要することが課題でした。本技術では図2に示すように、人が遠隔操作によりロボットに必要な動作を複数回教示し(Step1)、さらに計算機内で数時間学習するだけで(Step2)、所望の動作をプログラミングレスで獲得できる手法を開発しました。ロボットが作業を実行する際には(Step3)、学習内容である過去の経験を想起し現実と比較、実世界に即した必要な動作をリアルタイムに予測することで、未学習の環境や作業対象物に対応することが可能になりました。本技術の有効性を検証するために、一例として、実ロボットを用いた「ドア開け通過動作」を選定しました。人が日常的に行っているドア開けという簡単な動作でも、外見からのドアの認識に加え、ドアの動かし方(引く、押す)、ドアの構造(右開き、左開き)、ドアノブの位置・形状に応じた動作を検討する必要があり、人の脳はこれら一連の動作を過去の経験から適切かつ瞬時に判断します。一方で、ロボットでドア開けをする場合には、すべての状況に対応するために膨大な動作学習やプログラムを記述する必要がありました。これに対し本技術は、多種多様な用途・条件下で適用が可能であり、所望の動作を複数回教示するだけで、未学習のドアの模様やドアノブの位置、形状に対しても、ロボットが適切にドア開け動作を実行できることを確認しました。
3. 複数予測モデルのリアルタイム切替技術

図3 複数予測モデルのリアルタイム切替技術
1つの予測モデルでは対応しきれない複雑な作業に対応可能
複数工程にまたがる作業をロボットが実行するためには、想定される一連動作の流れに加え、想定外の状況への対応を別にプログラムする必要があるため、多くの開発費やロボットの調整作業が必要でした。また、作業環境に想定外の外乱が生じた場合は、ロボットが状況の変化を認識し、作業を再計画するために多くの計算を要し、ロボットの機能停止や作業時間が増加する問題がありました。本技術では、ロボットは「ドアを開ける」「通過する」といった個別動作ごとに予測モデルを記憶し、それらを組み合わせて一連の作業を実現します。各予測モデルはセンサからの情報を用いて、近未来の状況を示す予測画像を生成し、実際のロボットの視覚画像(実画像)と比較することで(Step1)、現実の状態にどの程度の正確性で作業可能かを示す指標(確信度)の時間変化をリアルタイムに計算します(Step2)。さらに、最も確信度が高い予測モデルをロボットが自律的に選択することで(Step3)、状況に適した行動を実行します。ロボットはこれらの計算をリアルタイムに行うため、動作を切り替えるタイミングや動作の流れを正確に設計することなく、1つの予測モデルでは対応しきれない複雑な作業に対応可能になりました。
- *1
- Horoshi Ito, Kenjiro Yamamoto, Hiroki Mori, Tetsuya Ogata, “Efficient multitask learning with an embodied predictive model for door opening and entry with whole-body control”, Science Robotics, 6 April 2022, Vol 7, Issue 65
- *2
- 日立調べ。
- *3
- 自由エネルギー原理: 環境に対する予測可能性を上げるという原理によって、認識だけでなく行動も生成されるとする仮説に従った脳の理論
照会先
株式会社日立製作所 研究開発グループ

")