
2022-06-13 産業技術総合研究所
NEDOの「人と共に進化する次世代人工知能に関する技術開発事業」において、今般、産総研は、数式から自動生成した大規模画像データセットを用いて人工知能(AI)の画像認識モデル(学習済みモデル)を構築する手法を世界で初めて開発しました。
本手法は、AIが学習で使用する大量の実画像やそのプライバシーの確保、ラベル付けコストなど商業利用の際の課題を解消するとともに、実画像や人の判断を経た教師ラベルを用いる現在の手法と同程度以上の画像認識精度を実現しています。今後、自動運転や医療、物流などさまざまな環境のAI構築で応用が期待できます。
また産総研は、この技術の詳細を、2022年6月19日から24日まで米国・ニューオーリンズで開催される国際会議IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022で発表する予定です。
1.概要
人工知能(AI)技術の導入が期待される分野は多様であり、特に画像認識※1の技術は注目を集めています。しかし、製造や医療の現場などでは、AIの学習に必要な大量のデータを収集することが不可能なケースや、高いコストがかかるケースがあり、AI技術の導入にあたって障壁となっています。
この障壁を克服する手段の一つとして、大量のさまざまな実画像※2を用いてAIが事前に学習※3した画像認識モデル(学習済みモデル※4)を活用する取り組みが進んでいますが、学習させる画像によってはプライバシー侵害や、不適切に付与された教師ラベル※5が人種によって不公平な認識結果を出力するなど、データの透明性に関する問題があり、商業利用の際の課題となりつつあります。そのため、プライバシー侵害や不公平な認識結果など画像データ関連の問題を解決しつつ従来と同程度以上の認識精度を実現する学習済みモデルの開発は、AI分野において喫緊の課題となっていました。
そこで今般、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の「人と共に進化する次世代人工知能に関する技術開発事業※6」において、国立研究開発法人産業技術総合研究所(産総研)人工知能研究センター片岡裕雄 主任研究員らは、事前の学習で実画像を一切用いず、数式※7から画像パターンや教師ラベルを自動で生成することでラベル付けのコストを削減し、実画像のデータ数や倫理的な問題、権利関係を気にせずAIの画像認識モデル(学習済みモデル)を構築する手法を世界で初めて開発しました。さらに、この学習済みモデルで、画像認識性能のベンチマークに活用されるImageNet※8の画像データセットを認識させたところ、実画像や人の判断を経た教師ラベルを用いる現在の手法よりも精度が優れており、実利用できるレベルに達していることを確認できました。
本データセットおよび学習済みモデルは本日より、下記のHPで公開します。

また産総研は、この技術の詳細を、2022年6月19日から24日まで米国で開催される国際会議IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022で発表※9します。

図1 実画像や人の判断による教師ラベルを必要とせず、数式から生成した教師ラベルで学習された画像理解AIの概念図
2.今回の成果
今回、数式から自動生成した大規模画像データと自動で割り当てられる教師ラベルからなるデータセットを用い、AIの一手法である深層学習によって物体形状の基礎的な視覚特徴を学習することで、画像を認識するAIを容易に構築可能とする学習済みモデルを開発しました。
はじめに、汎用的な数式の一つであるフラクタル幾何※10によって自動生成した画像データセットを画像認識AIの学習に用いると、実画像と人間が与えた教師ラベルを用いた従来の学習と近い認識精度が出ることを明らかにしました。さらに、フラクタル幾何の画像データで学習した画像認識AIの学習の仕方を調べたところ、主に輪郭成分に着目して物体を識別することがわかりました。
そこで、画像の主要成分が輪郭となるよう、放射状に輪郭を生成する関数を数式に設定した画像データセット(輪郭形状による画像データセット)も構築しました。これらの画像データセットで学習させた結果、物体を識別するための基礎的かつ良好な視覚特徴を得ることができました。 また、この手法では、数式から画像が生成される際に自動で教師ラベルが生成されるため、従来のような実画像に人が教師ラベルを付与する手間は不要となります。
識別検証には、画像認識のベンチマークとされるImageNetを用いました。ImageNetは1000個のカテゴリに分類された一般物体画像のデータセットです。インターネット上の画像データとして頻出するさまざまな画像タイプを含んでいるため、ImageNet画像を認識問題(タスク)として与えて認識精度を見ることで、実利用レベルを測ることができます。
検証ではまず、図2に示すように、従来の人が教師ラベルを付与した標準的な実画像データセットと、今回開発したフラクタル幾何による画像データセット、輪郭形状による画像データセットのそれぞれで学習済みモデルを生成し、画像認識AIを構築しました。この画像認識AIにImageNetの一般的な物体の画像をタスクとして与えた結果、フラクタル幾何および輪郭形状による画像データセットで構築した画像認識AIの精度は、実画像によるものより高い水準(フラクタル幾何:82.7%、輪郭形状:82.4%、実画像81.8%)を記録しました。

図2 学習済みモデルを生成するために用いた画像例。
図の上部は従来用いられていた標準的な実画像、図の中央および下部は今回提案の数式(フラクタル幾何・輪郭形状)から生成した画像。
さらに、フラクタル幾何による数式は拡張することができます。例えば、図3左は3D空間における物体検出を目的とした数式から生成された3Dフラクタルデータです。この拡張したデータセットを実空間の3Dデータを用いた学習済みモデルに追加学習させることができます。図3右は部屋内の3Dスキャンデータからの家具検出の例であり、ロボットが部屋内を移動する際などに使用できます。
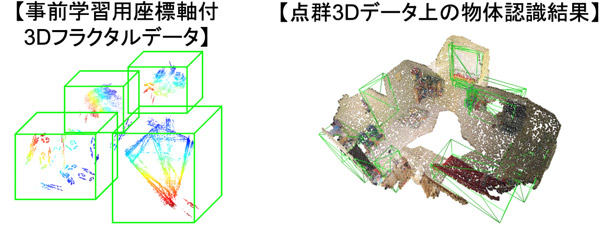
図3 3D空間における物体検出のために拡張したデータセット
以上より、数式からフラクタル幾何や輪郭形状の画像データセットを用いて学習済みモデルを構築する手法は、さまざまな物体が存在する実空間での実用化が必要となる自動運転やロボットの視覚能力への応用が期待できます。
また、今回の研究成果である学習済みモデルを公開することで、利用者は、一定の精度を持つ画像理解AIから開発をスタートできます。
なお、学習済みモデルの学習には、産総研が保有する世界最大規模の人工知能処理向け計算インフラストラクチャであるAI橋渡しクラウド「AI Bridging Cloud Infrastructure(ABCI)」を活用しています。
3.今後の予定
本事業では、学習済みモデルの公開を通して、さまざまな産業分野でのニーズを聞き取りながら、動画や距離情報が含まれた画像など入力データを拡張するとともに、モーション認識や画像領域推定などより多くのタスクにも対応します。
また、数式からデータと教師ラベルを生成するという概念は、画像認識AIの開発に広く利活用できるポテンシャルがあります。これを生かし、実データや人が判断した教師ラベルを用いなくてもあらゆるタスクにおいて基盤となる「汎用学習済みモデル」を開発する予定です。同モデルは今後、医療分野や物流現場、交通シーン解析などさまざまな環境でAIを構築する際に役立つと考えられます。
図4 今後の展開イメージ
注釈
- ※1 画像認識
- 画像識別タスクや3D物体検出などを指します。画像や3D空間を入力して物体ラベルを出力します。
- ※2 実画像
- 現実世界をカメラで撮影した自然画像などを指します。
- ※3 学習
- AIに対して入力画像に何が映っているかを答えさせることを指します。正解もしくは不正解の答え合わせによりAI自体が賢くなります。
- ※4 学習済みモデル
- 100万画像以上など大規模な教師ラベル付けの画像データセットを用いて学習した画像理解タスクを既に知っているモデルのことで、他の画像理解タスクへの応用を容易にすることができます。
- ※5 教師ラベル
- 深層学習のモデルを学習できる形式にするために、画像に対して付与したタグ情報のことです。例として、画像に対して動物や人工物の種類を与えるなどが挙げられます。
- ※6 「人と共に進化する次世代人工知能に関する技術開発事業」
- 事業概要:https://www.nedo.go.jp/activities/ZZJP_100176.html
- ※7 数式
- 画像パターンと教師ラベルを生成するための生成規則です。今回は、フラクタル幾何や輪郭形状による数式を用いています。
- ※8 ImageNet
- 1000種類のカテゴリ(犬や猫の種類、工具など)が含まれた一般物体認識タスクを提供する画像データセットです。
- ※9 国際会議IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022で発表
- CVPR 2022に採択された2件の論文情報は下記の通りです。
論文1:Replacing Labeled Real-image Datasets with Auto-generated Contours
著者:Hirokatsu Kataoka, Ryo Hayamizu, Ryosuke Yamada, Kodai Nakashima, Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue, Rio Yokota
論文2:Point Cloud Pre-training with Natural 3D Structures
著者:Ryosuke Yamada, Hirokatsu Kataoka, Naoya Chiba, Yukiyasu Domae, Tetsuya Ogata - ※10 フラクタル幾何
- 部分と全体の構造が再帰的に類似するという自己相似性の特徴を有するものです。比較的単純な数式から複雑な画像パターンを構成可能であるという性質を用いて、産総研では数式により複雑形状を見分けるタスクを設定し、画像理解AIを訓練する枠組みを構築しました。
お問い合わせ
産業技術総合研究所


