")
2023-10-06 ワシントン大学セントルイス校
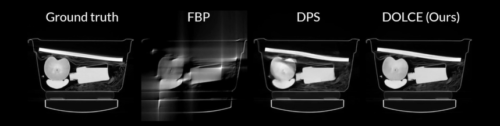
Figure 1: Illustration of slices from a luggage reconstructed using Filtered Back Projection (FBP), Diffusion Posterior Sampling (DPS), and the proposed DOLCE method. Note the remarkable accuracy of the DOLCE reconstructions that preserve fine details.
◆DOLCEは、限定的なデータから高品質な画像を生成するために最新の生成AIモデルを使用し、同時に再構築の不確実性を定量化するツールを提供します。このツールは、実際のデータと一致し、物理的な特性とも一致するため、生成モデルとしての優れた性能を発揮します。
◆DOLCEは、航空機の受託手荷物のスキャンや人体の医療画像など、さまざまなアプリケーションで高品質な画像再構築を向上させる有望なツールです。特に、物理的または時間的な制約のためにすべてのアングルを収集することが不可能なアプリケーションに適しています。この技術は、生成モデルを活用して最新の計算画像技術を革新しました。
<関連情報>
- https://source.wustl.edu/2023/10/meet-dolce-an-ai-tool-that-reconstructs-ct-images-from-limited-view-data/
- https://wustl-cig.github.io/dolcewww/
DOLCE: 限定角度CT再構成のためのモデルベースの確率的拡散フレームワーク DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
Jiaming Liu, Rushil Anirudh, Jayaraman J. Thiagarajan, Stewart He,K. Aditya Mohan, Ulugbek S. Kamilov, Hyojin Kim
International Conference on Computer Vision (ICCV), Oct. 2-6, 2023
Abstract
Limited-Angle Computed Tomography (LACT) is a non-destructive 3D imaging technique used in a variety of applications ranging from security to medicine. The limited angle coverage in LACT is often a dominant source of severe artifacts in the reconstructed images, making it a challenging imaging inverse problem. Diffusion models are a recent class of deep generative models for synthesizing realistic images using image denoisers. In this work, we present Diffusion Probabilistic Limited-Angle CT Reconstruction (DOLCE) as the first framework for integrating conditionally-trained diffusion models and explicit physical measurement models for solving imaging inverse problems. DOLCE achieves the SOTA performance in highly ill-posed LACT by alternating between the data-fidelity and sampling updates of a diffusion model conditioned on the transformed sinogram. We show through extensive experimentation that unlike existing methods, DOLCE can synthesize high-quality and structurally coherent 3D volumes by using only 2D conditionally pre-trained diffusion models. We further show on several challenging real LACT datasets that the same pre-trained DOLCE model achieves the SOTA performance on drastically different types of images.
