言語学者とコンピュータ科学者が協力して、大規模なグローバルオープンアクセスレキシカルデータベースを公開 Linguists and computer scientists collaborate to publish a large global Open Access lexical database
2022-06-16 マックス・プランク研究所
<関連情報>

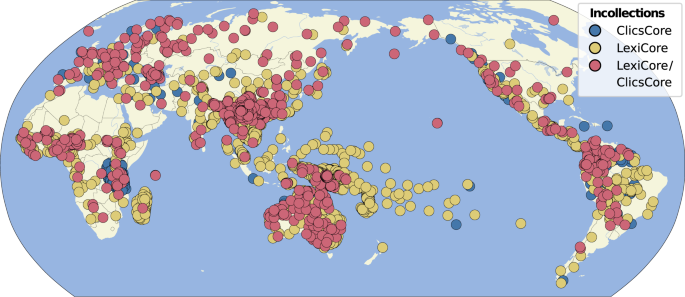
音韻と語彙の特徴を計算した標準的な単語リストのパブリックリポジトリ「Lexibank」 Lexibank, a public repository of standardized wordlists with computed phonological and lexical features
Johann-Mattis List,Robert Forkel,Simon J. Greenhill,Christoph Rzymski,Johannes Englisch & Russell D. Gray
Scientific Data Published:16 June 2022
DOI:https://doi.org/10.1038/s41597-022-01432-0
")
Abstract
The past decades have seen substantial growth in digital data on the world’s languages. At the same time, the demand for cross-linguistic datasets has been increasing, as witnessed by numerous studies devoted to diverse questions on human prehistory, cultural evolution, and human cognition. Unfortunately, most published datasets lack standardization which makes their comparison difficult. Here, we present a new approach to increase the comparability of cross-linguistic lexical data. We have designed workflows for the computer-assisted lifting of datasets to Cross-Linguistic Data Formats, a collection of standards that make these datasets more Findable, Accessible, Interoperable, and Reusable (FAIR). We test the Lexibank workflow on 100 lexical datasets from which we derive an aggregated database of wordlists in unified phonetic transcriptions covering more than 2000 language varieties. We illustrate the benefits of our approach by showing how phonological and lexical features can be automatically inferred, complementing and expanding existing cross-linguistic datasets.
| Measurement(s) | expressions |
| Technology Type(s) | data aggregation |
| Factor Type(s) | none |
| Sample Characteristic – Organism | human language |
| Sample Characteristic – Location | global scale |
")