GANを利用した自動アノテーションと果実検出モデルの構築
2021-06-01 東京大学
- 発表者
- 郭 威 (東京大学大学院農学生命科学研究科附属生態調和農学機構 助教)
Zhang Wenli (北京工業大学 情報学部 教授)
Shi Yun (中国農業科学院 中国農業科学院農業資源与農業区画研究所 教授)
発表のポイント
- 画像から特定の物体を検出するAI(注1)を作る際に、最大のボトルネックである手作業でのラベル付け(アノテーション作業・注2)を省略するアルゴリズムを開発した。
- 本手法を使って、アノテーション作業なしで、ミカン果樹園やトマト温室の写真から高精度に果実を検出するAIが構築できた。
- 多大な労力が必要となるアノテーション作業が不要となり、スマート農業技術の中核となる物体検出AI技術が加速的に発展することが期待される。
発表概要
東京大学大学院農学生命科学研究科附属生態調和農学機構の郭威助教らは、中国農業科学院、北京工業大学と共同で、アノテーション作業がなくても果実検出AIモデルの作成が可能となるアルゴリズムを提案した。
果実の検出と計数は、園芸のスマート化にとって不可欠な作業であり、深層学習(注3)に基づく果実の自動検出技術の近年の発展はめざましい。しかし、これまでの深層学習に基づく果実検出モデルの多くは、完全な教師あり学習 (注4)に基づいて生成されているため、特定の対象(果物や品種など。以下、ドメインと呼ぶ)で学習したモデルを他のドメインに利用することはできない。そのため、常に新しいドメインに対して、時間と労力を要するアノテーション作業を行って教師データを再作成する必要があった。つまり、果物ごとに、人間が大量の画像にラベル付けをしてAIに学習させる必要があった。
そこで本論文では、あるドメインで学習した既存のモデルを、新たなアノテーションをせずに新しいドメイン用に、検出精度を落とすことなく変換できるモデル汎化法を提案した。本手法を利用すれば、異なる作物種、異なる品種など、従来教師データ再構築が必要だった場合でも、アノテーション作業無しで果実検出モデルの作成が可能となるなど、AIを活用したスマート農業技術の実用化を加速することが期待できる。
発表内容

図1 本研究が提案する果実を自動アノテーション手法の詳細
入力:すでにアノテーション済のソースデータセットとアノテーションされていない目標データセット。
出力:自動的にアノテーションされたデータセット。

図2 本研究が提案する果実を自動アノテーションするための画像生成結果
左:ミカン園で撮影された写真 中:生成されたリンゴの写真 右:生成されたトマトの画像

図3 本研究における果実検出結果
上:りんご園で撮影した画像 下:トマト温室で撮影した画像
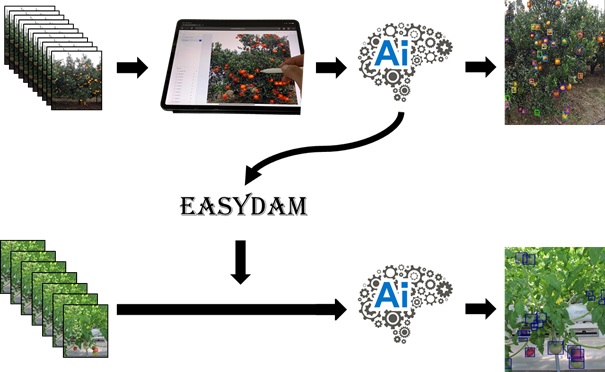
図4 本研究が提案されたEASYDAMを利用するイメージ
園芸において、果実の数、大きさ、色など、果実に関連する形質を理解することは重要であるが、コンピュータ技術の急速な発展に伴い、農業における物体検出技術も急速に向上している。物体検出技術は、果実の位置決め、収量予測、自動収穫など、果樹園におけるスマート農業の技術基盤となる。近年急速に発展する深層学習を用いた物体検出技術は、高い検出精度と撮影条件の変化に対する頑健性を備えていることから、従来の検出手法に代わって、果樹園の果実検出に広く適用されている。 一方、深層学習による果物検出技術の多くは教師あり学習を採用しており、モデルを学習するために、手作業に依存するアノテーション作業を行ってラベル付きの果物画像データセットを大量に用意する必要がある。しかし、ある果実種を対象として、膨大なデータを集め、アノテーション作業を行って深層学習モデルを作成しても、新しい対象目標となった他の果実種にはそのまま適応することはできない。新しい対象となった果実種に対してアノテーション作業とモデルの再学習を改めて行う必要があり、経済的にも時間的にも非常にコストがかかる。このように、検出モデルを作成するときのアノテーション作業による教師データの作成は、果実検出のようなAI開発のボトルネックとなっている。
これまでも、アノテーション作業コストを削減するために、能動学習 (注5)を用いた弱教師あり学習、合成データを用いた学習など、様々な手法が提案されてきたが、手作業がまだ必要であることや検出精度が実用レベルに満たないなどの課題が残されてきた。
そこで本研究では、深層学習技術の一つであるGAN(注6)を用いて、新たな対象の画像データをアノテーション済みのデータへ変換し疑似ラベル化することで自動的にアノテーション作業を行い、更に自動的に精度も向上させる手法を開発した(図1)。そして、ミカン園で取得され、ミカン果実についてアノテーション作業が行われた画像データとミカン果実検出モデルを、全くアノテーション作業を行っていないリンゴ園で撮影された画像と温室で撮影されたトマト画像へ適応し検証した(図2)。新たに構築された検出モデルは、ミカン園と似ている野外撮影環境で得られたリンゴ園画像での検出精度が87.5%、全く撮影環境が異なる温室トマト画像での検出精度でも76.9%を達成し、本提案による果実検出の汎用性が高いことが示唆された(図3)。
本研究成果は、経済的にも時間的にも非常にコストがかかるアノテーション作業が無くても果実検出モデルが構築できることを示したものである。本成果により、公開されている既存の果実検出のためのアノテーション済みデータセット(本論文Table6に記載、すでに公開された、りんご、マンゴー、トマトなど果実検出論文及び入手可能なリンクを参照)を適切に利用すれば、自分の対象作物圃場の画像を取得するだけで、迅速に自分の対象作物圃場に最適な果実検出モデルを作成できる可能性があるなど、スマート農業技術の中核となるAIモデルの汎用化へ貢献が期待できる(図4)。
発表雑誌
- 雑誌名
- Horticulture Research
- 論文タイトル
- Easy domain adaptation method for filling the species gap in deep learning-based fruit detection
- 著者
- Zhang, Wenli*, Chen, Kaizhen, Wang, Jiaqi, Shi Yun, Guo, Wei*(*責任著者)
- DOI番号
- 10.1038/s41438-021-00553-8
- 論文URL
- https://www.nature.com/articles/s41438-021-00553-8
問い合わせ先
東京大学大学院農学生命科学研究科附属生態調和農学機構
助教 郭 威(カク イ)
用語解説
注1 AI
Artificial Intelligence(人工知能)。ただ現時点では、専門家や研究者の間でも「人工知能」に関する確立した学術的な定義、合意はない。
注2 アノテーション作業
深層学習モデルの作成のための教師データを作り出す作業。例えば、画像中で自動認識したい果実とそれ以外の部分を学習用データとして、目視で準備する必要がある。
注3 深層学習
Deep learning。AIの発展を支える機械学習の手法のひとつとして挙げられる。
注4 教師あり学習
人間が用意した正解データ(教師データ)を与えてモデルを学習させる機械学習の方法。本文では、アノテーション済のデータは教師あり学習ための教師データを意味する。
注5 能動学習
Active Learning。アノテーションされていない画像データから深層学習モデルの高精度化に有効なデータを選択して学習する手法。これにより、アノテーション作業数を削減し、ひいては教師データの作成コストを削減できる。
注6 GAN
Generative Adversarial Network(敵対的生成ネットワーク)。GANは生成モデルの一種であり、既存の画像から特徴を学習することで、実に存在しない画像を生成できる。

を開発し、輪作に適したダイズ品種を推定")