
様々なAI技術の判断精度向上に貢献
2020-07-13 株式会社富士通研究所
株式会社富士通研究所(注1)は、AIによる検知・判断における精度向上に向け、高次元データの分布・確率などの本質的な特徴量を正確に獲得するAI技術「DeepTwin(ディープツイン)」を世界で初めて開発しました。
近年、様々なビジネスの領域において、膨大かつ多様なデータをAIで解析する需要が急激に増加しています。通常、AIの学習には大量の教師データが必要となりますが、教師データの作成に要する時間・工数などのコストがかかるため、正解ラベルを付与しない教師なし学習の必要性が増しています。しかし、通信や画像など、扱うデータが高次元の場合は、データの特徴を獲得するのが計算量の観点で困難なため、ディープラーニングを使って入力データの次元を削減する手法が用いられていました。ところが、この従来の手法では、次元削減後の空間における各データの分布や発生確率を考慮せずに削減していたため、入力データの正確な特徴量を捉えきれておらず、AIが誤った判定を行ってしまうといった問題がありました。
今回、当社は、情報通信分野において長年培ってきた映像圧縮技術の知見とディープラーニングを融合させることで、高次元データの削減すべき次元数と次元削減後のデータの分布をディープラーニングで最適化し、データの特徴量を正確に抽出できるAI技術を開発しました。本技術により、AI分野の重要な課題の一つである、データの正確な分布や発生確率の獲得が可能となるため、異常データ検知など様々なAI技術の判断精度向上に貢献し、幅広いビジネス領域におけるAI適用が期待されます。
本技術の詳細は、7月12日(日曜日)から開催される機械学習の国際会議「ICML 2020 (International Conference on Machine Learning 2020)」にて発表します。
開発の背景
近年、様々なビジネスの領域において、膨大かつ多様なデータをAIで解析する需要が急増し、AIの活用がますます期待されています。例えば、ネットワーク経由で実行される通信アクセスにおいて、日々変化する未知の不正アクセスによる攻撃が問題となっていますが、膨大な通信アクセスデータから通常とは挙動が異なる不正アクセスを教師なし学習で自動的に検知する仕組みが求められています。また、甲状腺数値や不整脈データなどの医療データにおいても、一般的に異常データの症例が少ない上にバラつきが大きいことから、異常データの検知をAIでサポートすることが期待されています。
課題
数学における空間の広がりを示す指標である次元は、私たち人間が生活しているx(幅)、y(高さ)、z(奥行)の3方向の広がりを表す3次元の空間のほか、点のみの空間である0次元から、通信データのような数十次元、画像データのような数百万次元など、さまざまなものが考えられます。
多くの業務で用いられるデータは、高次元データであり、データの次元数が増えると、データの特徴を正確に捉えるための計算の複雑さが指数関数的に増大してしまうことが、「次元の呪い(注2)」として広く知られています。近年、これを回避する手法として、ディープラーニングを使って入力データの次元を削減する手法が有望とされていますが、削減した後のデータ分布や発生確率を考慮せずに削減していたため、データの特徴を忠実に獲得できておらず、AIの認識精度の限界や誤判定が発生するといった問題がありました(図1)。これらを解決し、高次元データの分布・確率を正確に獲得することが、AI分野における重要な課題の一つとなっています。
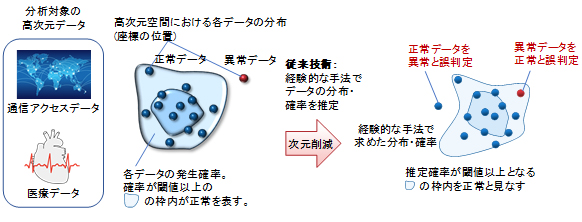
図1 従来の課題(異常検知の例):定量的な裏付けのない経験的な手法のため、誤った判定が発生
開発した技術
今回、当社が長年培ってきた映像圧縮技術の知見を活かし、理論体系に基づいた情報圧縮技術とディープラーニングを融合させ、高次元のデータの削減すべき次元数と次元削減後のデータの分布をディープラーニングで最適化することにより、教師データなしでデータの特徴を正確に捉えるAI技術「DeepTwin」を世界で初めて開発しました。
開発した技術の特長は以下の通りです。
- データの特徴を正確に獲得する理論の証明
数千から数百万次元の高次元データである画像や音声データの情報圧縮では、長年の研究でデータの分布や発生確率が解明されており、これらの既知の分布や確率に対して最適化された離散コサイン変換(注3)などの手法で次元数を削減する方法がすでに確立されています。そして、次元削減後のデータの分布と発生確率を用いてデータを復元すると、元の画像・音声と復元後の画像・音声との間の劣化を一定に抑えた時に、圧縮データの情報量を最も小さくできることが理論的に証明されていています。
今回、この理論から着想を得て、通信アクセスデータや医療データなど、分布・確率が未知の高次元データに対し、その次元をニューラルネットワークの一つであるオートエンコーダ(注4)で削減した後、また復元したときに、元の高次元データと復元後のデータとの間の劣化を一定値に抑えつつ、次元削減後の情報量を最小化したデータは、元の高次元データの特徴を正確に捉え、かつ、次元を最小限に削減できていることを世界で初めて数学的に証明しました。
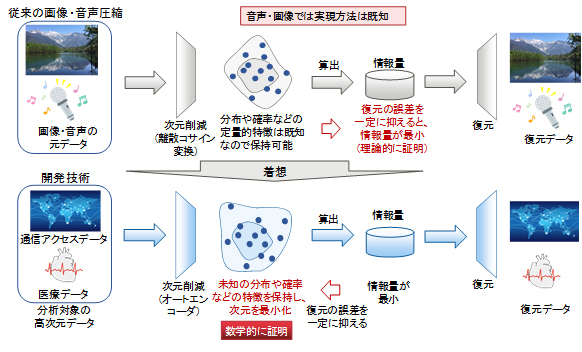
図2 情報圧縮技術に着想を得た、データの特徴に忠実な分布・確率の獲得の理論フレームワーク
- ディープラーニングを用いた次元削減技術
一般にディープラーニングは、最小化したい評価項目を定めると、複雑な問題でも評価項目が最小となるパラメータの組合せを求めることが可能です。この特徴を利用し、高次元データの削除すべき次元数と削除後のデータの分布を制御するパラメータを導入し、圧縮後の情報量を評価項目に定め、ディープラーニングで最適化しました。これにより、上記1の数学理論に基づいて最適化されたときの次元を削減したデータの分布および確率は、データの特徴を正確に捉えることが可能となります。
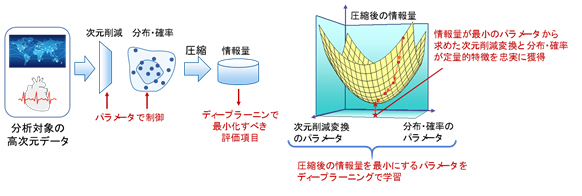
図3 次元削減変換および分布・確率を求めるディープラーニング技術
効果
今回、本技術をデータマイニングの国際学会「Knowledge Discovery and Data Mining (KDD)」が配布している通信アクセスデータ、およびカリフォルニア大学アーヴァイン校が配布している甲状腺数値データ、不整脈データといった異なる分野での異常検知のベンチマークで、従来のディープラーニングベースの誤り率と比較して最大で37%改善し、全データで世界最高精度を達成しました。本技術は、データの特徴を正確に捉えるというAIの根本的な課題を解く技術であるため、幅広い分野でのAI適用が期待できます。
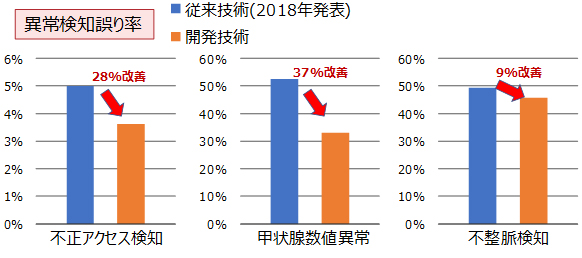
図4 異常検知に本技術を適用した場合の誤り率の改善
今後
今後、当社は、開発した技術の実用化を進め、2021年度中の実用化を目指すとともに、さらに多くのAI技術に適用していきます。また、その成果を富士通のAI技術「FUJITSU Human Centric AI Zinrai(ジンライ)」に活用していきます。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
以上
注釈
- 注1 株式会社富士通研究所:
- 本社 神奈川県川崎市、代表取締役社長 原 裕貴。
- 注2 次元の呪い:
- データの次元数が増えると、計算の複雑さが指数関数的に増大してしまうこと。
- 注3 離散コサイン変換:
- 画像・音声信号を周波数成分の強度に変換するフーリエ変換の一種。
- 注4 オートエンコーダ:
- ニューラルネットワークに基づく教師無しの次元圧縮技術。
本件に関するお問い合わせ
株式会社富士通研究所
人工知能研究所

