2024-08-27 東京大学
発表のポイント
- 自然界に現れる様々な階層的構造は木構造によって表現されます。本研究は、木構造を生成する確率モデルである確率文脈依存文法の統計的性質を、シミュレーションを用いて明らかにしました。
- 木構造を生成する確率モデルとしては、従来、確率文脈自由文法がよく調べられていましたが、このモデルには強い制限があります。この制限を破り、より豊かな表現力を持つ確率文脈依存文法を系統的に調べたのは、本研究が初めてです。
- 本研究は、より複雑な木構造の研究に向けた第一歩となるものです。また、解析のため導入された新たな指標は、様々なモデルや自然現象の背後にある木構造のより深い探究を可能にします。

(左)自然言語の背後にある階層的な文法構造。
(右)数理モデルによって生成された、植物の成長を模した階層的な構造。
概要
東京大学大学院総合文化研究科の中石海(博士課程3年)と福島孝治教授は、木構造(注1)を生成する確率モデルである確率文脈依存文法(注2)の統計的性質をシミュレーションを用いて明らかにしました。
様々な現象の背後にある階層的な構造は木構造と呼ばれるグラフによって表現されます。木構造を確率的に生成するモデルとして、従来は確率文脈自由文法(注3)がよく調べられてきましたが、このモデルには強い制限があり、表現できる木構造が限られていました。
本研究は、この制限を破り、より豊かな表現力を持つモデルとして、確率文脈依存文法の統計的性質を調べました。その結果、確率文脈自由文法との様々な違いを定量的に明らかにしました。
本研究は確率文脈依存文法の振る舞いを初めて系統的に調べました。これは、より複雑な木構造の研究に向けた第一歩と言えます。また、本研究は確率文脈自由文法における制限がどれだけ破られているかを測る指標を新たに導入しました。この指標は、様々なモデルや自然現象の背後にある木構造を定量的に特徴づける新たな手法を提供します。
発表内容
【背景】
自然言語(注4)や植物の成長、RNA(注5)など、多くの自然現象の背後には階層的な構造があります。このような構造はしばしば木構造を用いて表現されます。木構造はノード(頂点)とエッジ(辺)からなるグラフです。各ノードはその下にあるいくつかのノードとエッジでつながっており、上側にあるノードは親ノード、下側にあるノードは子ノードと呼ばれます。このような構造が階層的に繰り返されます(図1)。
木構造を確率的に生成するモデルの代表例として、確率文脈自由文法が挙げられます。このモデルは、根と呼ばれるひとつのノードから出発して、親ノードから子ノードへと、順番に木構造を生成していきます。このモデルの統計的性質は非常によく調べられています。また、自然言語や RNA の構造の推定に利用されています。
しかし、確率文脈自由文法は、どのような子ノードが生成されるかが親ノードのみによって決まるという強い制限を持っています(図1)。一般に、自然現象がこのような制限を満たしているとは限りません。実際、自然言語の構造は、確率文脈自由文法をそのまま使うだけではうまく表現できないことが知られています。
そのため、より現実の現象に近い階層構造を理解するためには、子ノードの生成が親ノード以外のノードにも依存するような、より複雑なモデルを考えることが必要です。ところが、そのようなモデルの統計的性質は、これまで十分に調べられてきませんでした。
【研究内容】
本研究は、確率文脈自由文法の自然な拡張である確率文脈依存文法の統計的性質を、シミュレーションを用いて調べました。確率文脈依存文法のもとでは、子ノードは、親ノードだけでなくその隣のノードにも依存します(図1)。
シミュレーションの結果、確率文脈自由文法と質的に異なる振る舞いが発見されました。具体的には、構造上のふたつのノード間の相関の振る舞いに違いが見られました。確率文脈自由文法では、相関は木構造上での距離が大きくなるにつれて減少します。一方、確率文脈依存文法では、構造上での距離が大きかったとしても相関は必ずしも弱くなりません。しかし、子ノードが親ノードの隣のノードとも直接的に相関することを考慮すると、木構造上での距離の定義を修正することができます。確率文脈依存文法における相関は、この定義し直された距離が大きくなるにつれて減少します。
さらに本研究は、子ノードが親ノードのみによって決まるという条件がどれだけ破られているかを定量的に表す指標を新たに導入しました。この指標は確率文脈自由文法では常にゼロであり、一方、確率文脈依存文法では正の値をとります。この結果もまた、確率文脈自由文法と確率文脈依存文法の違いを定量的に特徴づけるものです。
【今後の展望】
確率文脈依存文法の振る舞いを系統的に調べたのは本研究が初めてであり、本研究は、子ノードが親ノード以外のノードにも影響するようなやり方で生成される木構造の振る舞いを理解するための第一歩と言えます。今回の結果はシミュレーションの観察にもとづくものであるため、観察されたさまざまな振る舞いがなぜ生じるのかを説明するための、より詳細な解析が今後の課題です。
また、本研究で導入された、子ノードが親ノード以外の要素にどれだけ依存しているかを表す指標は、確率文脈自由文法や確率文脈依存文法に限らない一般の数理モデルや自然現象に対して適用できます。したがって、例えば自然言語などの現象が、確率文脈自由文法の条件をどのように、どれだけ破っているのか、この指標によって定量的に測定することができます。このように、本研究の提案する新たな指標は、確率文脈自由文法では表せない、より複雑なモデルや現象を研究するうえで有用です。
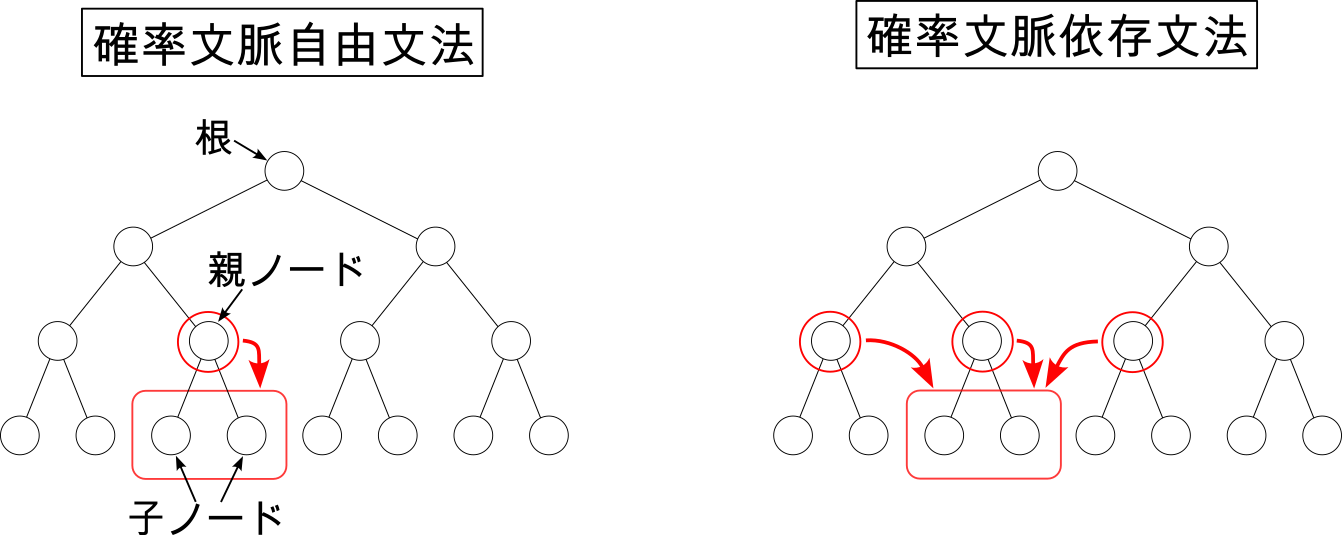
図1:確率文脈自由文法と確率文脈依存文法による木構造の生成。確率文脈自由文法においては、子ノードは親ノードのみに依存して決まる。一方、確率文脈依存文法においては、親ノードと隣り合ったノードも子ノードに影響する。
発表者・研究者等情報
東京大学大学院総合文化研究科
中石 海 博士課程
福島 孝治 教授
論文情報
雑誌名:Physical Review Research
題名:Statistical properties of probabilistic context-sensitive grammars
著者名:Kai Nakaishi*、 Koji Hukushima
DOI:10.1103/PhysRevResearch.6.033216
URL:https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.033216
研究助成
本研究は、科研費「特別研究員奨励費(課題番号:23KJ0622)」、科研費「基盤研究(B)(課題番号:23H01095)」、「共創の場形成支援プログラム(課題番号:JPMJPF2221)」、東京大学 先進基礎科学推進 国際卓越大学院教育プログラムの支援により実施されました。
用語説明
(注1)「木構造」
ノード(頂点)とエッジ(辺)からなるグラフ。各ノードはその下にあるいくつかのノードとエッジでつながっており、上側にあるノードは親ノード、下側にあるノードは子ノードと呼ばれる。
(注2)「確率文脈依存文法」
木構造を確率的に生成するモデル。文脈依存文法と呼ばれる形式文法の確率化。
(注3)「確率文脈自由文法」
木構造を確率的に生成するモデル。文脈自由文法と呼ばれる形式文法の確率化。確率文脈依存文法よりも表現力が弱いが、性質がよく調べられている。もともとは自然言語の文法構造を表現するために導入されたが、その後、自然言語に限らず、階層構造を持つ多くの現象のモデルとして利用されている。
(注4)「自然言語」
日本語、英語など、人間が日常において使う言語。プログラミング言語や数式といった人工的な言語と区別する目的で、この用語が用いられる。
(注5)「RNA」
リボ核酸(Ribonucleic acid)。生物の遺伝情報の伝達、遺伝情報にもとづくタンパク質の合成において本質的役割を果たす。一次元の鎖状をしているが、一部の構成要素が互いに結合することで折りたたまれ、特異的な構造をとる。

