
")
2023-09-12 マサチューセッツ工科大学(MIT)
◆この新しいモデルは、自動運転車両などのエッジデバイスでのリアルタイム物体認識に役立つ可能性があります。また、医療画像セグメンテーションなどの高解像度コンピュータビジョンタスクの効率も向上させることができます。
<関連情報>
- https://news.mit.edu/2023/ai-model-high-resolution-computer-vision-0912
- https://arxiv.org/pdf/2205.14756.pdf
EfficientViT: 軽量マルチスケールアテンションによる オンデバイス・セマンティック・セグメンテーション EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation
Han Cai, Junyan Li, Muyan Hu, Chuang Gan, Song Han
arxiv 6 Apr 2023
Abstract
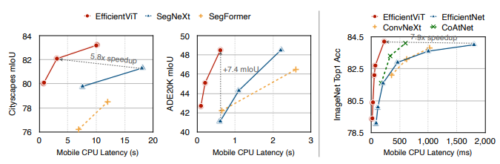
Semantic segmentation enables many appealing realworld applications, such as computational photography, autonomous driving, etc. However, the vast computational cost makes deploying state-of-the-art semantic segmentation models on edge devices with limited hardware resources difficult. This work presents EfficientViT, a new family of semantic segmentation models with a novel lightweight multi-scale attention for on-device semantic segmentation. Unlike prior semantic segmentation models that rely on heavy self-attention, hardware-inefficient large-kernel convolution, or complicated topology structure to obtain good performances, our lightweight multiscale attention achieves a global receptive field and multiscale learning (two critical features for semantic segmentation models) with only lightweight and hardware-efficient operations. As such, EfficientViT delivers remarkable performance gains over previous state-of-the-art semantic segmentation models across popular benchmark datasets with significant speedup on the mobile platform. Without performance loss on Cityscapes, our EfficientViT provides up to 15× and 9.3× mobile latency reduction over SegFormer and SegNeXt, respectively. Maintaining the same mobile latency, EfficientViT provides +7.4 mIoU gain on ADE20K over SegNeXt.

")
")