2023-06-08 新エネルギー・産業技術総合開発機構,株式会社
NEDOは「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」(以下、本事業)に取り組んでおり、その一環として、(株)エヌエスアイテクスは、(株)OTSL、(株)日立製作所、東京工業大学と共同で、エッジコンピューティング領域における次世代組み込みシステム向け人工知能(AI)処理プロセッサー(DILP:Dynamic Instance Link Processor)を開発しました。
本プロセッサー技術で実際の畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)アプリケーションを実行したところ、世界最高クラスとなる1W(ワット)当たり15TOPS(15兆回/秒)の評価値を達成しました。これは現在実用化されている技術の5倍以上に相当する電力効率です。また、面積効率でも1mm2当たり1.36TOPS(1.36兆回/秒)の高評価値を実現しています。さらに、今回の成果の実用性検証として、ロボットアームを用いたリアルタイム物品仕分けの実証を行いました。その結果、DILP適用によるロボットアーム移動経路の探索時間が従来の制御方法に比べて10分の1以下になり、本プロセッサーが産業分野の自動化に貢献できるめどが立ちました。
これにより、さらなる省スペース、低消費電力、高性能多機能化が求められている自動車、ファクトリーオートメーション(FA)・ドローンなどの制御系、また、監視カメラなどを中心とする組み込みシステムへ広く適用が期待できます。

図1 DILPを活用したシステム構成
1.背景
AIを組み込み領域などのシステムの末端(エッジ)で利用する際には、AI処理の90%以上を占める畳み込み演算を、エッジシステムという限られた計算資源や電力制約の下、効率的に処理することが重要で、加えてAI処理の前後処理では、データの型変換やスケーリング(正規化)処理に高い並列処理性能が望まれます。膨大なAI処理計算を実行するだけでなく、信号処理・制御なども必要なため、非対称な処理を効率よく実行できるプロセッサーが求められます。また、こうしたプロセッサーをエッジで広く実用化するにあたり、プロセッサーのハードウエア性能だけでなく、その性能を引き出すためのソフトウエア実行環境の実現も不可欠です。このような背景の下、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)は2018年度から本事業※1において、「革新的AIエッジコンピューティング技術の開発」に取り組んでいます。その一環として、株式会社エヌエスアイテクスは株式会社OTSL、株式会社日立製作所、国立大学法人東京工業大学と共同で、次世代組み込みシステム向けAI処理プロセッサーの開発に取り組んでいます。
2.今回の成果
今回、高電力効率を実現した次世代組み込みシステム向けAI処理プロセッサーを開発し、産業機械分野での応用実証に成功しました。
本プロセッサーは、既存のプロセッサー技術と比べて5倍以上に相当する電力効率で世界最高クラスの1W当たり15TOPS(15兆回/秒)の評価値を実現しました。また、面積効率の評価では1mm2当たり1.36TOPS(1.36兆回/秒)という極めて高い演算処理効率のプロセッサーであることも確認しました(下表)。
さらに、今回の成果の実用性検証として、ロボットアームを用いたリアルタイム物品自動仕分けの実証を行いました。この実証は工場や建設現場の労働人口減少に伴い自動化が急務となってきていることを想定したものです。その結果、DILPを適用したロボットアームの移動経路の探索時間は、従来の制御方法に比べて10分の1以下になり、本プロセッサーが産業分野の自動化に貢献できるめどが立ちました。
今回の成果は、AIエッジを中心とした次世代の多様なアプリケーションを効率よく実行するプロセッサーの開発に成功したといえるものです。このアクセラレーターはフレキシブルかつスケーラブルな構造により複数世代にわたり利用可能です。高電力効率・高面積効率の実現により、電力消費許容量やサイズといった装置搭載条件の厳しい組み込み系システム、具体的には、自動車、FA・ドローンなどの制御系、また、監視カメラなどを中心とするIoT関連に広く適用が期待できます。
3.開発した技術の詳細
【1】高電力効率を実現するプロセッサーの開発
本プロセッサーは、エッジでAI処理を行う際に並列コンパイラー※2にてグラフ構造※3で表された処理内容の各枝部分をスレッド化し、ハードウエアではそのスレッド※4を実行条件が整った順に同時に実行する構造です。また、図1に示すように組み込みシステムにおいては、汎用(はんよう)処理系を中央演算処理装置(CPU)が担い、本プロセッサーはAI処理のアクセラレーターを担います。このように異なる種類のプロセッサーを併用するヘテロジニアス※5な環境下において、さまざまなタスクを同時かつリアルタイムに処理するソフトウエア実行環境として、並列コンパイラーやハイパーバイザー※6機能を開発しました。
AI処理の代表的処理であるCNNにおいて高い電力効率を実現するために、本プロセッサーでは以下の三つの手法を適用しました。これらの方式自体は既知の手法ですが、本プロセッサーに対して独自の実装を行うことで、高い電力効率を実現しました。
- (1)Tiling & Layer-Fusion手法によりLayer-Fusionにおける重複演算を無くし演算量を従来比50%減
- Tiling & Layer-Fusion技術は、入力画像を分割(Tiling)し、分割したデータごとに複数のレイヤー処理の入出力を連結(Layer fusion)して処理することにより、中間データの外部メモリへの退避を削減し、電力効率を向上させる手法です。従来手法では単純なLayer fusionのため、重複した演算を実行する必要がありましたが、演算結果を再利用する独自方式を実装することにより重複演算を無くし、従来手法比で50%の演算量を削減できました。
- (2)Winograd’s minimal filter algorithmの独自実装で畳み込み層における演算量を従来比60%減
- Winograd’s minimal filterは、畳み込み演算の乗算回数を削減する手法です。本開発では、Winograd’s minimal filterのパラメーターを探索し、電力削減効果と回路面積のトレードオフ関係が最適となる5×5行列入力から直接3×3行列を出力する構成を見いだし、畳み込み演算量を従来手法比で60%削減しました。
- (3)特異値分解による低ランク化を全結合層(フルコネクション層)に適用して演算量を従来比17%減
- フルコネクション層の行列演算に特異値分解による低ランク化を適用しました。本手法は一般的に適用されるプルーニング(Pruning)※7と異なり、ゼロ検出して演算をスキップする処理が不要でありベクタプロセッサーで効率よく演算が可能となり高電力効率の実現に寄与しています。フルコネクション層の行列演算の低ランク化はAI処理精度を評価しながら最適なパラメーターを探索し、フルコネクション層の演算量を従来手法比で17%削減しました。
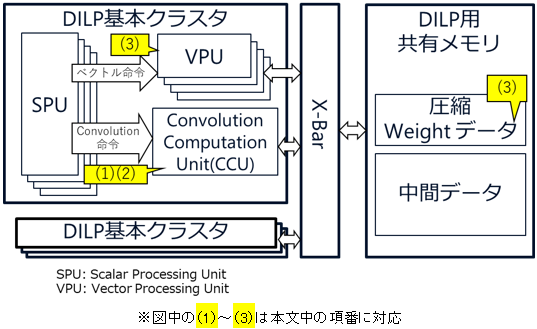
図2 高電力効率プロセッサーDILPの内部構成
以上の技術を7ナノメートル(nm)プロセス環境でDILPに実装することで、実際のCNN処理動作時に電力効率1W当たり15TOPSを実現することに成功しました。また、面積効率の評価では1mm2当たり1.36TOPSという極めて演算処理効率の高いプロセッサーであることも確認しました。
表 開発したプロセッサーの電力効率(左)と面積効率(右)

【2】ロボット制御環境での実証評価
今回開発したプロセッサーの実用性を検証するため、図3に示すロボットアームの制御に関するシステム実証環境を構築しました。この環境ではホスト側のCPU上のハイパーバイザーで動作する各リソースパーティション内のアプリケーションからDILPを呼び出すことが可能となっています。空間地図作成やロボットアームの移動経路探索アルゴリズムをFPGA※8に実装したDILPで実行させロボットアームをリアルタイムで制御しました。図4は実証環境で右上の黒い箱にDILPを含めたハードウエアが入っています。図5はロボットアームの動作状況で、右側ロボットアームがサッカーボール、バスケットボール、消しゴムを所定の位置に置いた後に、左側ロボットアームがサッカーボールを回収する様子です。DILPの適用によりロボットアーム移動経路の探索時間が従来の制御方法に比べて同一周波数で10分の1以下にできることを確認しました。これにより本プロセッサーが、FA分野をはじめ、産業分野での効率的な自動化に貢献できるめどが立ちました。
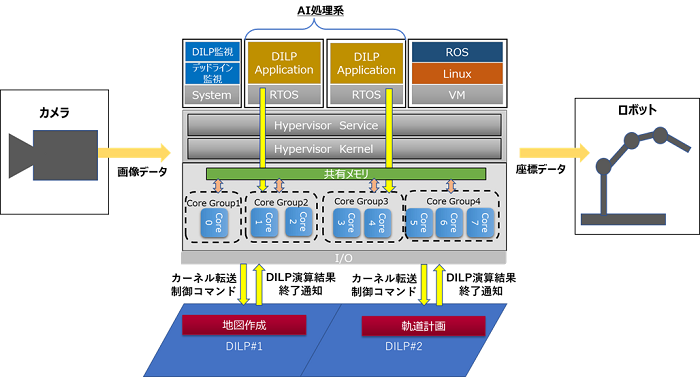
図3 ロボットアームの制御に関するシステム実証環境とフロー

図4 実証環境

図5 ロボットアームがサッカーボールを回収している様子
【注釈】
- ※1 本事業
-
- 事業名:高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発/革新的AIエッジコンピューティング技術の開発/動的多分岐・結合トレース型AIプロセッサのエコシステム開発
- プロジェクト期間:2018年度~2022年度
- 事業概要:高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発
- ※2 並列コンパイラー
- コンパイラーとはソースコードを機械語へ変換するツールです。C言語などのプログラムを入力として、特定のCPUの機械語を出力します。ストレート型、中間言語型の二つに大別されます。並列コンパイラーではユーザープログラムから並列構造を捉えこれをスレッド単位に分解して、ハードウエアの並列実行を引き出すための、コード変換を行います。
- ※3 グラフ構造
- ノード(頂点)とノードの間の連結を示すエッジ(枝)から成るデータ構造です。
- ※4 スレッド
- 並行処理に対応したマイクロプロセッサー(CPU/MPU)およびオペレーティングシステム(OS)におけるプログラムの最小の実行単位を指します。
- ※5 ヘテロジニアス
- 複数の異なる役割や仕様の装置や機器、ソフトウエアなどが同じシステム上に混在し、相互に連携しながら役割分担して機能する様子などを表します。
- ※6 ハイパーバイザー
- ハードウエアと複数OSの間に配置し、複数のリソースパーティションを使用して複数のアプリケーションやOSを同時に実行します。
- ※7 プルーニング(Pruning)
- ニューラルネットワークのパラメーター数を削減する手法の一つで、電子回路の高電圧と低電圧の区別や、プログラミングの条件分岐などで用いられる閾値(しきいち)以下の重みをネットワークから取り除くことで処理量を削減します。
- ※8 FPGA
- Field Programmable Gate Array(書き換え可能な論理回路デバイス)を搭載したハードウエア基板です。AIチップタイプ同様のAI処理専用回路を短TAT(Turn Around Time)に実装・開発できる特徴があります。
4.問い合わせ先
(本ニュースリリースの内容についての問い合わせ先)
NEDO IoT推進部 担当:大坪、岩佐
(株)エヌエスアイテクス 事業推進部 担当:伊藤、片野
(その他NEDO事業についての一般的な問い合わせ先)
NEDO 広報部 担当:坂本、瀧川、黒川、橋本、根本

