")
2023-04-06 アメリカ合衆国・コーネル大学
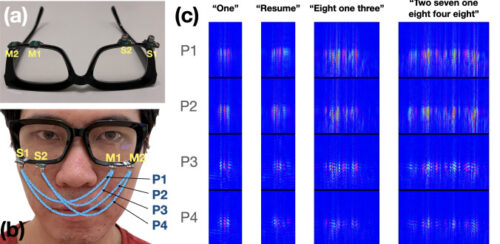
・ コーネル大学の Smart Computer Interfaces for Future Interactions (SciFi)ラボが、市販のメガネによる音響センシングと AI を利用して最大で 31 種類の無声音コマンドの連続認識が可能なサイレントスピーチ認識(SSR)インターフェイス、「EchoSpeech」を開発。
・ 同ラボが別途開発した、顔の動きを追跡する音響センシングデバイスのイヤホン「EarIO」がベース。SSR 技術の多くでは予め決められたコマンドの選択に限定され、ユーザーによるカメラとの対面や装着が必要なため実用性に欠ける。
・ 低電力消費、プライバシーを考慮したウェアラブルインターフェイスで、わずか数分間のユーザートレーニングデータによりコマンドを認識し、スマートフォンで作動する。さらなる進展により、サイレントスピーチ技術は音声合成用の優れたインプットとなり、発声回復に役立てることも可能となる。
・ 現行のバージョンでは、賑やかなレストランや静かな図書館等の発話が困難・不適当な場所でのスマートフォンを介したコミュニケーションに利用できる。また、タッチペンとのペアリングも可能で CAD 等の設計ソフトでも使用でき、キーボードやマウスが不要に。
・ 鉛筆に付いた消しゴムよりも小さなマイクとスピーカーを搭載した「EchoSpeech」メガネは、ウェアラブ
ルな AI 駆動のソナーシステムとして顔面を通過する音波を送受信し、口の動きを検出。SciFi ラボ開発の深層学習アルゴリズムがこれらの反響のプロファイルを約 95%の精度でリアルタイム分析する。
・ SciFi ラボでは、機械学習と小型ビデオカメラを使用して身体、手、顔の動きを追跡するウェアラブルデバイスも開発している。カメラを音響センシングで代替することで、電池寿命、セキュリティー・プライバシーを向上させ、より小型でコンパクトなハードウェアを実現した。
・ 音響データは画像・動画データよりも大幅に小さいためより、狭い帯域幅で処理でき、Bluetooth を介してスマートフォンへリアルタイム送信できる。スマートフォンでローカルにデータを処理するため、プライバシーに関する機微情報を保守できる。音響センシングの電池寿命は 10 時間(カメラの場合は 30 分)。
・ コーネル大学の Ignite: Cornell Research Lab to Market gap ファンディングを通じ商業化を進める。今後は顔、目と上半身の挙動を追跡するスマートメガネアプリケーションを開発する予定。本研究は米国立科学財団(NSF)が一部支援した。
URL: https://news.cornell.edu/stories/2023/04/ai-equipped-eyeglasses-can-read-silent-speech
<NEDO海外技術情報より>
関連情報
Association for Computing Machinery Conference on Human Factors in Computing Systems (CHI) 発
表論文(フルテキスト)
EchoSpeech: Continuous Silent Speech Recognition on Minimally-obtrusive Eyewear Powered by
Acoustic Sensing
URL: https://ruidongzhang.com/files/papers/EchoSpeech_authors_version.pdf
ABSTRACT
We present EchoSpeech, a minimally-obtrusive silent speech interface (SSI) powered by low-power active acoustic sensing. EchoSpeech uses speakers and microphones mounted on a glass-frame
and emits inaudible sound waves towards the skin. By analyzing echos from multiple paths, EchoSpeech captures subtle skin deformations caused by silent utterances and uses them to infer silent speech. With a user study of 12 participants, we demonstrate that EchoSpeech can recognize 31 isolated commands and 3-6 figure connected digits with 4.5% (std 3.5%) and 6.1% (std 4.2%) Word Error Rate (WER), respectively. We further evaluated EchoSpeech under scenarios including walking and noise injection to test its robustness. We then demonstrated using EchoSpeech in demo applications in real-time operating at 73.3mW, where the real-time pipeline was implemented on a smartphone with only 1-6 minutes of training data. We believe that EchoSpeech takes a solid step towards minimally-obtrusive wearable SSI for real-life deployment.
")
")