2023-11-09 富士通株式会社
当社は、生成AIや深層学習などの需要の高まりによる世界的なGPU不足に対応するため、このたび、GPUを活用したプログラム処理中においても、高い実行効率が見込める処理に対してリアルタイムかつ優先的にGPUを割り振ることで、CPUとGPUの計算リソースを適切に活用可能な世界初の技術(以下、アダプティブGPUアロケーター技術)を開発しました。これにより、利用者は、先行しているGPUでのプログラム処理を終えるまで待つ必要がなくなるほか、CPUで処理が始まっているプログラムに対してもGPUの利用状況を踏まえてリアルタイムにGPUへ切り替えることが可能になり、高効率なGPU利用を実現します。
また、複数のコンピュータを協調動作させ大規模な計算を行うHPCシステムにおいて、実行中のプログラムの完了を待たずに、複数プログラムの処理をリアルタイムに切り替えることで並行処理を可能にする世界初の技術(以下、インタラクティブHPC技術)も開発しました。これにより、大規模な計算リソースとリアルタイム性が求められるデジタルツインや生成AIといったプログラムの処理を即時に実行することが可能になります。
当社は、社会課題の解決と持続可能な社会を実現するイノベーションの創出につながるコンピューティング基盤の実現に向けて、お客様の解きたい問題に対して計算時間や演算精度、コストといった要件に応じてAIが最適なコンピュータを自動で選択し演算可能な、現在開発中のソフトウェア構想「Computing Workload Broker」の一部として今回開発した技術を提供し、お客様との検証を進めていきます。
当社はこれらの技術について、2023年11月12日(日曜日)から米国コロラド州デンバーのコロラドコンベンションセンターにて開催される「SC23」において、アダプティブGPUアロケーター技術やインタラクティブHPC技術のデモンストレーションを行うほか、インタラクティブHPC技術についてはリサーチポスターセッションでも発表します。
背景
現在、高精度なシミュレーションやAI予測を活用する研究開発においては、スーパーコンピュータやGPUといった高性能な計算機が利用されています。しかし、多くの場合、複数のユーザが計算機を共有利用しているため、プログラム処理中に別のプログラムを処理すると、メモリ不足によるエラーや複数計算機間の同期タイミングのずれによる計算速度の大幅な低下を招いていました。そのため、プログラムごとに計算リソースを割り当てプログラム終了後に次のプログラムを処理するため、リアルタイム性が求められるデジタルツインや生成AIへの活用が困難でした。
特に、深層学習などでGPUの需要が高まる一方、GPUで処理した方が高速化するプログラムにもかかわらず、GPUリソースや他のプログラム処理などの影響で、GPUの利用がプログラムの一部のみに留まっているなど、低効率な利用が存在することも課題でした。
今回開発した技術の特長
1. プログラム処理実行中においてもCPUとGPUを使い分ける世界初の技術(アダプティブGPUアロケーター技術)
複数のプログラム処理を実行中の場合においても、GPUを必要とするプログラム、CPUで処理しても良いプログラムを、高速化率を予測するなどして区別し、優先度の高いプログラム処理に対してリアルタイムにGPUを割り振る世界初の技術を開発しました。
例えば図1のように、3つのプログラム処理をCPU1台、GPU2台で効率的に行いたい場合、GPUの空き状況に応じてプログラム1と2にGPUを割り振ります。その後、プログラム3のリクエストに応じ、性能計測のためにGPUの割り当てをプログラム1から3に変更し、GPUでの処理高速化の度合いを計測します。計測の結果、プログラム1より3にGPUを割り当てた方が全体としての処理時間の短縮化につながることが判明したことで、プログラム3にGPUをそのまま割り振り、プログラム1にはその間CPUを割り振ります。プログラム2の終了後はGPUに空きができるため、再度GPUをプログラム1に割り当てており、このような形で、最短でプログラム処理が完了するように計算リソースを割り振ることを実現します。
これにより、GPUを利用するAIや高度な画像認識などのアプリケーション開発において、グラフAIデータを処理するモデルの学習などを素早く実施することが可能になります。
 図1. CPUとGPUの割り当て切り替えのイメージ
図1. CPUとGPUの割り当て切り替えのイメージ
2. HPCシステム上で複数プログラムのリアルタイムな実行切り替えを行う世界初の技術(インタラクティブHPC技術)
複数台のコンピュータを協調動作させるHPCシステムにおいて、現在実行中のプログラムの完了を待たずに利用可能とする、複数のプログラムのリアルタイムな実行切り替えを行う世界初の技術を開発し、リアルタイム性が求められるプログラムの実行にHPCシステムを利用することが可能になります。
従来の制御方式は各サーバへプログラム実行を切り替える通信を一つひとつ行うユニキャスト通信を利用しているため、切り替えタイミングのばらつきが発生し、リアルタイムでのプログラム実行の一括切り替えが困難でした。今回、プログラム実行を切り替える通信に一斉送信可能なブロードキャスト通信を採用することで、従来、性能面への影響から実用的にはプログラムの実行切り替え間隔は秒単位であったところを、256ノードのHPC環境において100ミリ秒へと短縮でき、リアルタイムでのプログラム実行の一括切り替えを実現しました。なお、適切な通信方式はアプリケーションの要件やネットワーク品質によって変わるため、ブロードキャスト通信による性能向上とパケットロスによる性能低下の度合を鑑みて、最適な通信方式を選択可能です。
これにより、デジタルツインや生成AI、材料・創薬探索などの分野におけるリアルタイム性が求められるアプリケーションを、HPC並みの計算リソースを用いてより高速に実行することが可能になります。
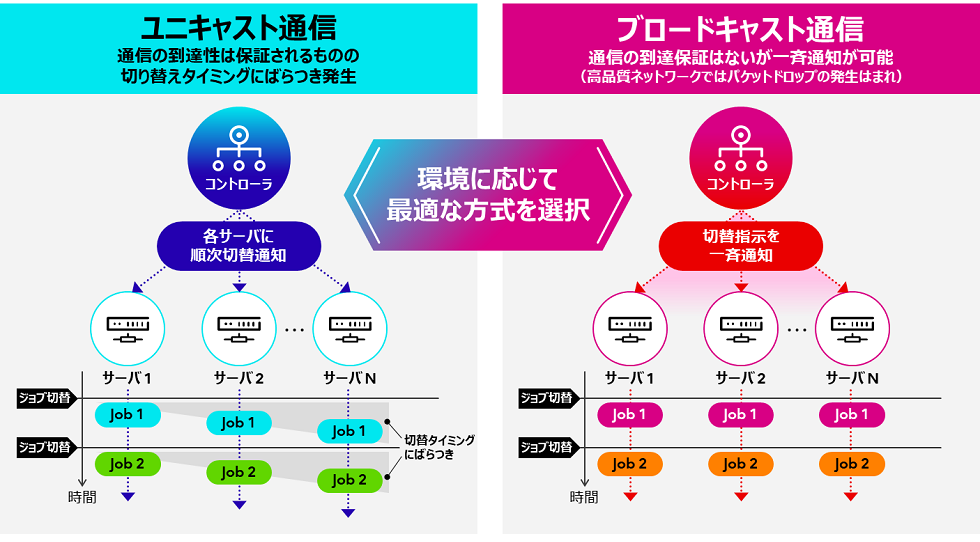 図2. プログラムの実行切り替えに用いる通信方式の違い
図2. プログラムの実行切り替えに用いる通信方式の違い
今後について
当社は今後、アダプティブGPUアロケーター技術については、先端AI技術を素早く試せる「Fujitsu Kozuchi (code name) – Fujitsu AI Platform」におけるGPUが必要な処理において活用していく予定です。また、インタラクティブHPC技術については、当社の40量子ビットの量子コンピュータシミュレータにおいて、多数のノードを用いた協調計算を行う部分へ適用予定です。
さらに、シミュレーションやAI、組合せ最適化問題のアプリケーションを開発、実行可能な「Fujitsu Computing as a Service HPC」や、サーバ間でハードウェア構成を変更可能な技術であるComposable Disaggregated Infrastructure(CDI)アーキテクチャへの適用も検討し、誰もがリーズナブルで高性能な計算機環境を容易に利用可能な社会の実現を目指します。
商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
本件に関するお問い合わせ
富士通コンタクトライン(総合窓口)

での半導体製造が地上にもたらすメリット(The Benefits of Semiconductor Manufacturing in Low Earth Orbit (LEO) for Terrestrial Use)")