
2025-07-29 ミシガン大学
<関連情報>
- https://news.umich.edu/why-ai-leaderboards-are-inaccurate-and-how-to-fix-them/
- https://aclanthology.org/2025.acl-long.1265/
- https://arxiv.org/abs/2312.14972
ランキングの解明:AI対決におけるLLMランキングのレシピ Ranking Unraveled: Recipes for LLM Rankings in Head-to-Head AI Combat
Roland Daynauth, Christopher Clarke, Krisztian Flautner, Lingjia Tang, Jason Mars
ACL Anthology Published:July 2025
DOI:https://aclanthology.org/2025.acl-long.1265/

Abstract
Evaluating large language model (LLM) is a complex task. Pairwise ranking has emerged as state-of-the-art method to evaluate human preferences by having humans compare pairs of LLM outputs based on predefined criteria, enabling ranking across multiple LLMs by aggregating pairwise results through algorithms like Elo. However, applying these ranking algorithms in the context of LLM evaluation introduces several challenges, such as inconsistent ranking results when using ELO. Currently there is a lack of systematic study of those ranking algorithms in evaluating LLMs. In this paper, we explore the effectiveness of ranking systems for head-to-head comparisons of LLMs. We formally define a set of fundamental principles for effective ranking and conduct extensive evaluations on the robustness of several ranking algorithms in the context of LLMs. Our analysis uncovers key insights into the factors that affect ranking accuracy and efficiency, offering guidelines for selecting the most appropriate methods based on specific evaluation contexts and resource constraints.
スケールダウンでスケールアップ:OpenAIのLLMを生産環境でオープンソースSLMに置き換えるコスト便益分析 Scaling Down to Scale Up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production
Chandra Irugalbandara, Ashish Mahendra, Roland Daynauth, Tharuka Kasthuri Arachchige, Jayanaka Dantanarayana, Krisztian Flautner, Lingjia Tang, Yiping Kang, Jason Mars
arXive last revised 16 Apr 2024 (this version, v3)
DOI:https://doi.org/10.48550/arXiv.2312.14972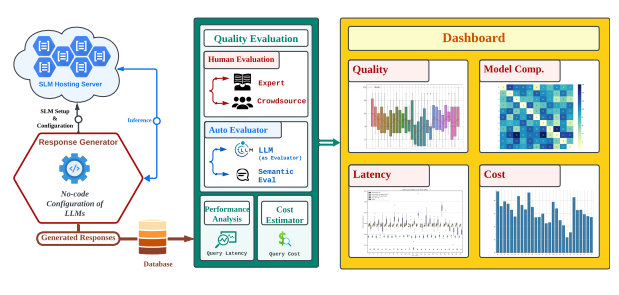
Abstract
Many companies use large language models (LLMs) offered as a service, like OpenAI’s GPT-4, to create AI-enabled product experiences. Along with the benefits of ease-of-use and shortened time-to-solution, this reliance on proprietary services has downsides in model control, performance reliability, uptime predictability, and cost. At the same time, a flurry of open-source small language models (SLMs) has been made available for commercial use. However, their readiness to replace existing capabilities remains unclear, and a systematic approach to holistically evaluate these SLMs is not readily available. This paper presents a systematic evaluation methodology and a characterization of modern open-source SLMs and their trade-offs when replacing proprietary LLMs for a real-world product feature. We have designed SLaM, an open-source automated analysis tool that enables the quantitative and qualitative testing of product features utilizing arbitrary SLMs. Using SLaM, we examine the quality and performance characteristics of modern SLMs relative to an existing customer-facing implementation using the OpenAI GPT-4 API. Across 9 SLMs and their 29 variants, we observe that SLMs provide competitive results, significant performance consistency improvements, and a cost reduction of 5x~29x when compared to GPT-4.

")
")