
2026-03-19 中国科学院瀋陽自動化研究所(SIA)
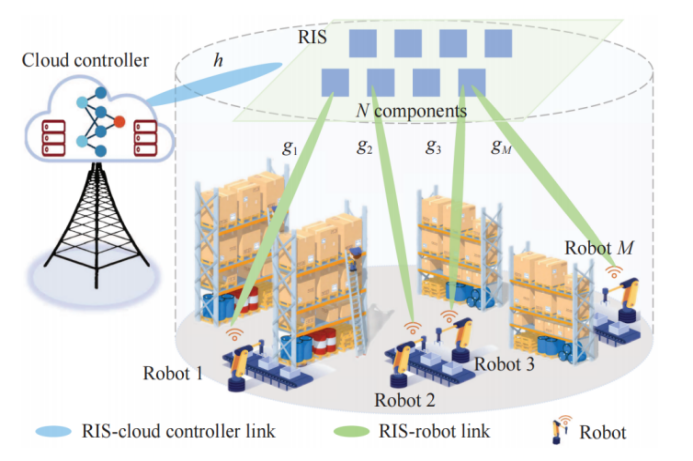
RIS-assisted Wireless Cloud Robotic System Architecture (Image by SIA)
<関連情報>
- http://english.sia.cas.cn/news/Research_Progress/202603/t20260319_1152941.html
- https://ieeexplore.ieee.org/document/11429638
マルチエージェント転移強化学習による無線クラウドロボットシステムの制御・通信協調最適化 Control-Communication Co-Optimization for Wireless Cloud Robotic System via Multi-Agent Transfer Reinforcement Learning
Chi Xu; Junyuan Zhang; Haibin Yu
IEEE/CAA Journal of Automatica Sinica Published:10 March 2026
DOI:https://doi.org/10.1109/JAS.2025.125894
Abstract
The wireless cloud robotic system (WCRS), which fully integrates sensing, communication, computing, and control capabilities as an intelligent agent, is a promising way to achieve intelligent manufacturing due to easy deployment and flexible expansion. However, the high-precision control of WCRS requires deterministic wireless communication, which is always challenging in the complex and dynamic radio space. This paper employs the reconfigurable intelligent surface (RIS) to establish a novel RIS-assisted WCRS architecture, where the radio channel is controlled to achieve ultra-reliable, low-delay, and low-jitter communication for high-precision closed-loop motion control. However, control and communication are strongly coupled and should be co-optimized. Fully considering the constraints of control input threshold, control delay deadline, beam phase, antenna power, and information distortion, we establish a stability maximization problem to jointly optimize control input compensation, RIS phase shift, and beamforming. Herein, a new jitter-oriented system stability objective with respect to control error and communication jitter is defined and the closed-form expression of control delay deadline is derived based on the Jensen Inequality and Lyapunov-Krasovskii functional. Due to the time-varying and partial observability of the channel and robot states, we model the problem as a partially observable Markov decision process (pOMDP). To solve this complex problem, we propose a multi-agent transfer reinforcement learning algorithm named LSTM-PPO-MATRL, where the LSTM-enhanced proximal policy optimization (PPO) is designed to approximate an optimal solution and the option-guided policy transfer learning is proposed to facilitate the learning process. By centralized training and decentralized execution, LSTM-PPO-MATRL is validated by extensive experiments on MuJoCo tasks for both low-mobility and high-mobility robotic control scenarios. The results demonstrate that LSTM-PPO-MATRL not only realizes high learning efficiency, but also supports low-delay, low-jitter communication for low error control, where 71.9% control accuracy improvement and 68.7% delay jitter reduction are achieved compared to the PPO-MADRL baseline.

")
の成長メカニズムに新知見(Study Offers New Understanding of How “Roof of the World” Grows)")