
")
2023-07-18 マサチューセッツ工科大学(MIT)
◆この手法は、シミュレーションでのテストにおいて他の方法よりもロボットの効率的な学習を可能にしました。このフレームワークは、技術的な知識を持つことなく、ロボットが新しい環境でより速く学習するのに役立つ可能性があります。将来的には、高齢者や障害を持つ人々が日常のタスクを効率的に行うための多目的ロボットの実現に向けた一歩となるでしょう。
<関連資料>
- https://news.mit.edu/2023/faster-way-teach-robot-technique-0718
- https://arxiv.org/pdf/2307.06333.pdf
診断、フィードバック、適応:テストタイムポリシー適応のためのヒューマン・ループ・フレームワーク Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation
Andi Peng, Aviv Netanyahu, Mark Ho, Tianmin Shu, Andreea Bobu, Julie Shah, Pulkit Agraw
arxiv
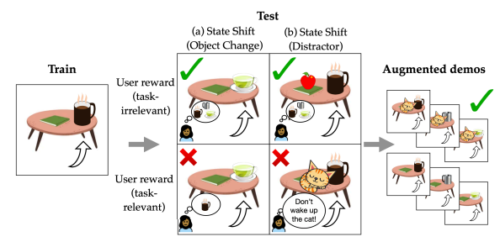
Abstract
Policies often fail due to distribution shift— changes in the state and reward that occur when a policy is deployed in new environments. Data augmentation can increase robustness by making the model invariant to task-irrelevant changes in the agent’s observation. However, designers don’t know which concepts are irrelevant a priori, especially when different end users have different preferences about how the task is performed. We propose an interactive framework to leverage feedback directly from the user to identify personalized task-irrelevant concepts. Our key idea is to generate counterfactual demonstrations that allow users to quickly identify possible task-relevant and irrelevant concepts. The knowledge of taskirrelevant concepts is then used to perform data augmentation and thus obtain a policy adapted to personalized user objectives. We present experiments validating our framework on discrete and continuous control tasks with real human users. Our method (1) enables users to better understand agent failure, (2) reduces the number of demonstrations required for fine-tuning, and (3) aligns the agent to individual user task preferences.

")
")